Multimodal AI: Mixing Text, Images, and Audio for Smarter Interactions
Imagine an AI that doesn’t just read text or look at pictures, but can do it all—read, listen, watch—and make sense of it like a human does. That’s multimodal AI, and it’s changing how machines interact with the world. Instead of handling one type of data at a time, these AIs combine text, images, audio, and even video to understand things more deeply and respond more naturally.
What is Multimodal AI?
Humans process information from all our senses—sight, sound, touch—at once. Multimodal AI tries to do the same, but with computers. It can take different types of input, like a photo, a voice recording, or a paragraph of text, and combine them to make smarter decisions.
The magic happens in data fusion—mixing information from different sources so the AI gets a fuller picture than it would from just one type of data. This fusion can happen in different ways, from combining raw inputs to merging the results of specialized AI models.
How Multimodal AI Works
A typical multimodal AI system has three main parts:
- Input Module: This is where data comes in. Text, images, and audio each have their own neural networks to understand their specific type of data. For example, text might go through a transformer model like GPT, images through a Vision Transformer (ViT) or CNN, and audio through something like Wav2Vec2.
- Fusion Module: Here’s the cool part—the AI blends all the information together. Good fusion strategies can make the AI up to 40% more accurate than just using one type of data.
- Output Module: Finally, the AI turns its understanding into something useful—answers, predictions, or actions.
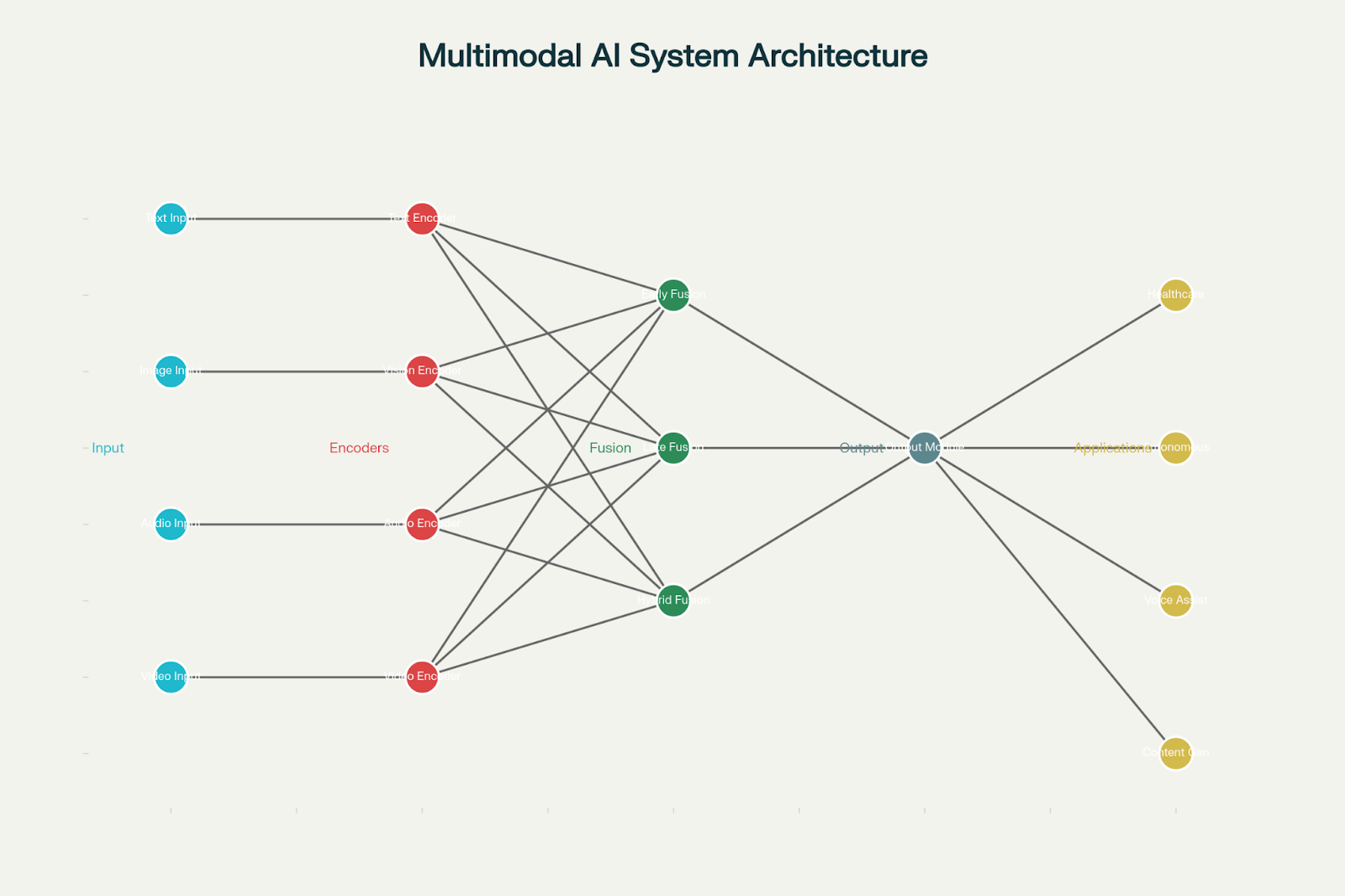
Multimodal AI System Architecture and Processing Pipeline
Ways to Fuse Data
- Early Fusion: Mix raw data together from the start. Great for closely linked inputs, but it needs a lot of computing power.
- Late Fusion: Process each type separately, then combine results. More flexible and fault-tolerant, but might miss how different inputs interact.
- Hybrid Fusion: Combines both approaches. For example, one modality can influence how another is processed using techniques like cross-modal attention.
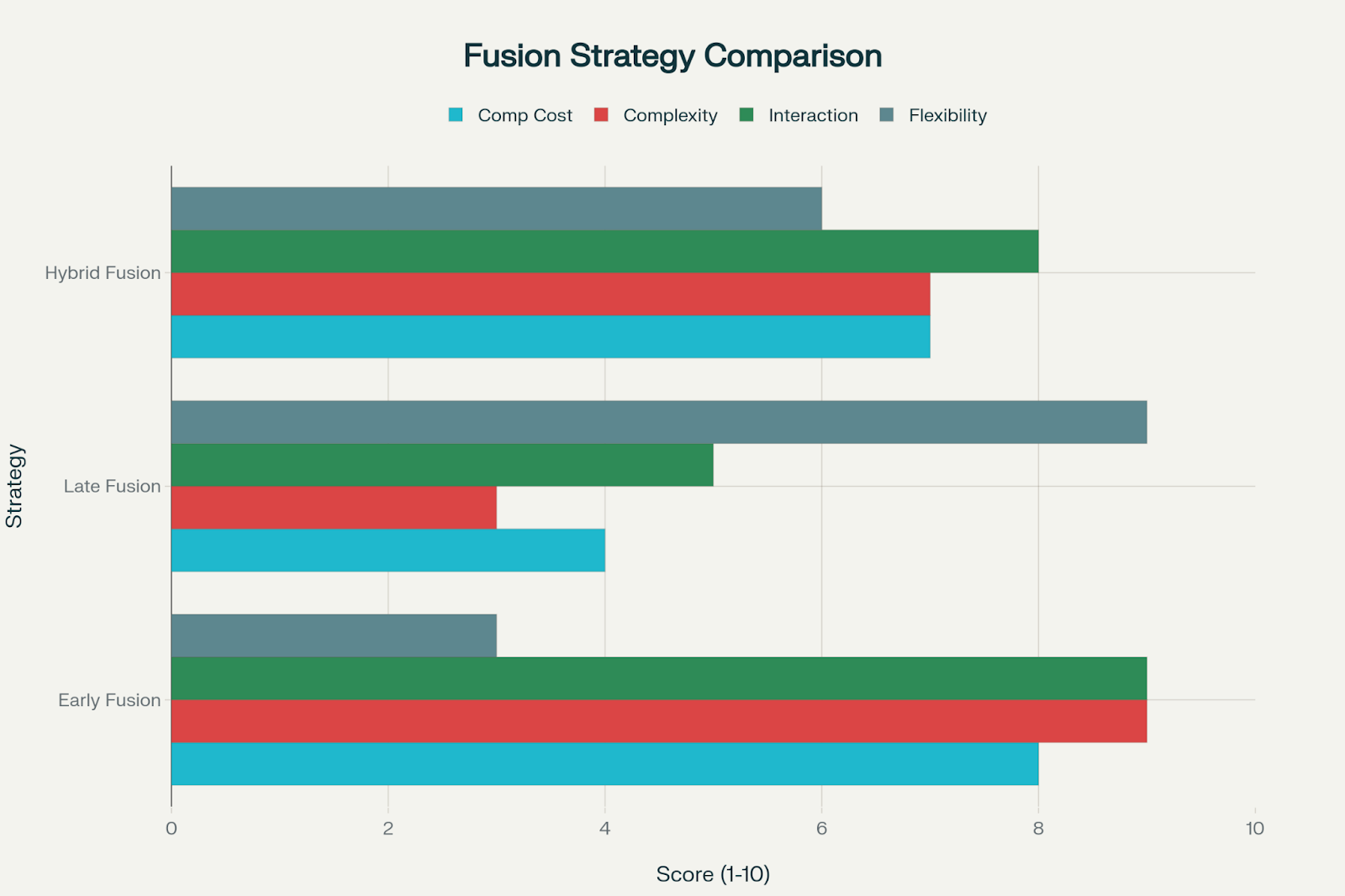
Comparison of Multimodal AI Fusion Strategies: Performance Characteristics
Transformers: The Backbone of Modern Multimodal AI
Transformers, which are the engines behind GPT and similar models, are naturally good at handling different types of data.
- Vision Transformers (ViTs): Treat images like sequences of text, breaking them into patches.
- Audio Transformers: Turn sound into visual-like spectrograms so the same methods can process audio, text, and images.
Popular Multimodal Models
- GPT-4o: Can process text, images, audio, and video in one model. Faster and cheaper than older systems. Great for things like real-time translation and analyzing live camera feeds.
- CLIP: Connects images and text in the same “embedding space,” allowing it to find pictures based on text descriptions.
- ImageBind (Meta): Handles six different types of data, from images to audio to thermal sensors.
- Gemini (Google DeepMind): Similar to GPT-4o, integrates text, images, audio, and video.
Real-World Applications
Healthcare: Multimodal AI can combine medical records, scans, and genetic data to improve diagnostics. For instance, Google’s MedPaLM 2 uses images and text to answer medical questions and detect diseases earlier.
Self-Driving Cars: Cars need cameras, LiDAR, radar, and GPS to navigate safely. Multimodal AI helps vehicles detect pedestrians, read signs, and make split-second decisions, even when one sensor fails.
Voice Assistants: Devices like Alexa and Google Assistant are moving beyond just voice. They can understand images and gestures too, making interactions smoother and more natural.
Smart Homes: AI can combine voice commands, camera feeds, and sensor data to create smarter, more intuitive homes—like recognizing family members, adjusting lighting, or alerting security issues.
Challenges
- Technical Hurdles: Aligning data from different sources is tricky. Models can struggle with spatial reasoning or combining modalities effectively.
- Computational Demands: Multimodal AI needs lots of processing power and memory, which can be expensive.
- Data Issues: Inputs can come in different formats and speeds, and bad data can cause mistakes.
- Ethics & Privacy: Multimodal AI can gather a lot of personal info, raising privacy concerns. Biases in the data can also be amplified.
The Future of Multimodal AI
- Smarter AI Agents: AI will plan and act across multiple modalities more independently.
- Robotics: Multimodal AI will power robots that can see, hear, and interact physically with the world.
- Hyper-Personalization: From shopping to healthcare, AI will tailor experiences to individual needs using multiple types of data.
- Accessibility: AI will better help people with disabilities using voice, gestures, and visual inputs combined.
Conclusion
Multimodal AI is making machines smarter, more context-aware, and more human-like in how they understand the world. While challenges like high computing needs, data alignment, and ethical concerns remain, the potential is huge—from healthcare and self-driving cars to smart homes and personal assistants.
Over the next decade, we can expect multimodal AI to move from experiments to everyday tools, making our interactions with technology more natural, intuitive, and intelligent.